
实时文本转语音模型在交互式语音服务领域有着广泛的应用,例如语音助手和智能音箱 等。但是,由于延迟方面存在严格的要求,企业在部署这些模型时通常面临重重挑战。
一流的文本转语音 (TTS) 合成系统通常采用两个神经网络模型,这些模型依次运行以生成音频。第一个模型从输入文本生成声学特征,例如声谱图。第二个模型是声码器,它采用第一个模型的中间特征并产生语音。Tacotron 2 通常用作第一个模型。
Myrtle.ai 的一篇新白皮书“使用英特尔® Stratix® 10 NX FPGA 实施 WaveNet 进行实时语音合成”着重介绍了第二个模型。这是一种先进的声码器,基于称为 WaveNet 的神经网络模型,可以生成逼真度接近人类的自然声音。
WaveNet 模型生成高质量语音的关键在于自回归环路,但对于实时应用来说,网络实施方面极具挑战性。通常,WaveNet 模型加速尚无法实现实时音频合成。通过使用英特尔 Stratix 10 NX FPGA 支持的模块浮点 (BFP16) 量化功能,Myrtle.ai 能够部署一个可实时合成 256 个 16 kHz 音频流的实时 WaveNet 模型。

WaveNet 架构,使用 s、r、a 和对阶跃、残差和音频通道进行参数化,使用 L 对层数进行参数化
我们在英特尔 Stratix 10 NX FPGA 上实施了 WaveNet 模型。除了输入阶段的 ConvTranspose1d 层之外,所有层均在 FPGA 上处理。预处理层不依赖任何之前生成的值,因此可以在核心自回归 WaveNet 循环之外执行。网络的其余部分在 FPGA 上运行,包括条件上采样层之后的 1×1 卷积层。这极大提升了整个网络的计算能力。
FPGA 处理架构
我们使用 Myrtle.ai 可编程 MAU 内核架构在 FPGA 上实施网络。MAU 内核是一个面向深度神经网络的可编程处理引擎,叠加在 FPGA 结构上,可提供运行时可配置且灵活的推理引擎。
strong style=”max-width: 100%; box-sizing: border-box !important;”>使用英特尔 Stratix 10 NX FPGA AI 张量块
英特尔 Stratix 10 NX FPGA 具有创新的 AI 张量块,其 INT8 每秒万亿次运算数(TOPS)比英特尔 Stratix 10 FPGA 系列中的其他 FPGA 高出 15 倍。为了使用英特尔 Stratix 10 NX FPGA AI 张量块高效实施 1D 卷积层,我们将块配置为“张量”模式。
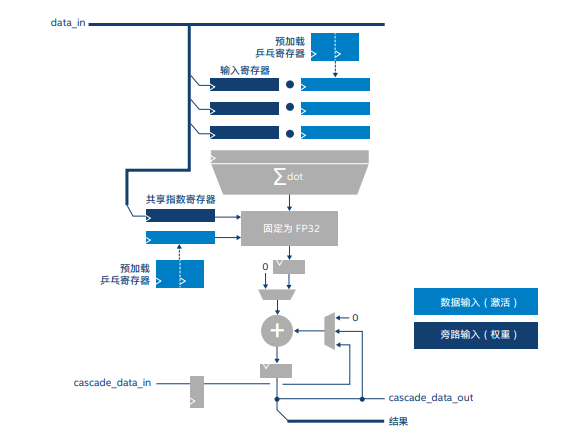
英特尔 Stratix 10 NX FPGA AI 张量块
在 FPGA 上实施扩张卷积
在推理过程中,我们使用快速 WaveNet 生成算法,将模型架构中的扩张卷积替换为常规卷积,并使用缓冲区来存储之前计算的值。然后,可以从缓冲区中选择正确的值来模拟扩张卷积。
编程模型
MAU 内核在运行时针对 WaveNet 模型进行编程,这支持将 FPGA 重复用于不同的模型架构,无需重新编译 FPGA 实施。
最新英特尔白皮书《基于英特尔® Stratix® 10 NX FPGA 的 WaveNet 助力实现实时语音合成》展示了具有 256 个并发语音通道的先进 WaveNet 模型如何使用基于专用 FPGA 的加速器,实现实时性能并生成接近人类水平的合成语音。相比当前可用的最佳 GPU 解决方案,该模型可将性能提升 8 倍。

点击“阅读原文”,即可免费下载完整白皮书!

文章来源于英特尔FPGA