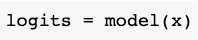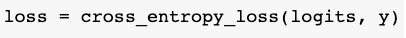当你使用PyTorch时,迁移到PyTorch Lightning会带来哪些好处,这篇文章会给你答案。
PyTorch易于使用,可以用来构建复杂的AI模型。但是一旦研究变得复杂,并且将诸如多GPU训练,16位精度和TPU训练之类的东西混在一起,用户很可能会写出有bug的代码。
PyTorch Lightning完全解决了这个问题。Lightning会构建您的PyTorch代码,以便抽象出训练的详细信息。这使得AI研究可扩展并且可以快速迭代。
PyTorch Lightning是为从事AI研究的专业研究人员和博士生所创建的。
Lightning由项目作者在攻读纽约大学博士学位(研究方向:CILVR及Facebook的AI研究)期间创建,拥有超过510名贡献者,核心团队由11名研究科学家,博士研究生和专业深度学习工程师构成。
该框架具有极强的可扩展性,同时又具备最先进的AI技术,如TPU训练等,降低使用难度。同时又提供简单接口,无论是专业团队或者新手菜鸟都能使用Pytorch、PyTorch Lightning社区开发最新技术。此外,核心贡献者也都在使用Lightning来推动AI的发展,并继续为其添加新的炫酷功能。

接下来我们通过构建一个简单的MNIST分类器为例,将PyTorch和PyTorch Lightning的代码进行对比。虽然Lightning可以构建任何任意复杂的系统,但我们使用MNIST来说明如何将PyTorch代码重构为PyTorch Lightning的代码。
示例完整代码可以从这里获取(https://colab.research.google.com/drive/1Mowb4NzWlRCxzAFjOIJqUmmk_wAT-XP3#scrollTo=x83-rnVKT8Wo)
在一个研究项目中,我们通常希望确定以下关键组成部分:
- 模型(model(s))
- 数据(data)
- 损失(loss)
- 优化器(optimizer(s))
我们设计一个三层的全连接神经网络,该网络以28×28的图像作为输入,并输出10个标签的概率分布。

该模型定义了一个计算图,将MNIST图像作为输入,并将其转换为数字0–9的10个类别的概率分布。

要将模型转换为PyTorch Lightning,我们只需将nn.Module替换为pl.LightningModule

新的PyTorch Lightning类与PyTorch完全相同,只是LightningModule为研究代码提供了结构(structure)。

这意味着我们可以像使用PyTorch的模块一样使用Lightning的模块,例如进行预测:



我们将MNIST数据集分成三个部分,即训练、验证和测试部分。
同样地,PyTorch中的代码与Lightning中的代码相同。
数据集被添加到数据加载器中,该数据加载器处理数据集的加载,打乱(shuffling)和批处理。
4.将每个拆分后的数据集包装在DataLoader中

再次强调,代码与PyTorch完全相同,只是我们将PyTorch代码组织为4个函数:
此函数进行数据下载和数据处理。此函数可确保当您使用多个GPU时,您不会下载多个数据集或对数据进行双重操作。
这是因为每个GPU将执行相同的PyTorch代码,从而导致重复。所有在Lightning中的代码可以确保关键的部分是仅由一个GPU来运行。
- train_dataloader, val_dataloader, test_dataloader
每一个函数都负责返回对应的数据集。Lightning以这种方式进行构造,因此非常清楚如何操作数据。如果你曾经阅读用PyTorch编写的随机github代码,你几乎看不到它们是如何操纵数据的。
Lightning甚至允许对于测试集或验证集创建多个数据加载器。
这部分代码被组织到DataModule之下。虽然这种方式百分百可选并且Lightning可以直接使用DataLoaders,但是DataModule使我们的数据可以重复使用并且易于共享。
接下来我们决定如何进行优化,我们将使用Adam而不是SGD,因为它在大多数DL研究中都是很好的默认设置。

同样,这两者的代码完全相同,只是Lightning把它组织到配置优化器的函数中。
Lightning可扩展性很强:例如,如果你想使用多个优化器(例如:GAN),则可以在此处返回两个优化器。

你可能还会注意到,在Lightning中,我们传入了self.parameters(),而不是模型,这是因为LightningModule本身就是模型。
对于n分类,我们要计算交叉熵损失。交叉熵与我们将要使用的NegativeLogLikelihood(log_softmax)相同。

- 模型(3层的神经网络)
- 数据集(MNIST)
- 优化器
- 损失
现在,我们执行一个完整的训练例程,该例程执行以下操作:
- 迭代多个epoch(一个epoch是对数据集的完整遍历)

-
每个epoch迭代批处理小块数据集
- 执行前向传播
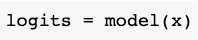
- 计算损失
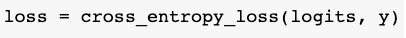
- 执行后向传播以计算每个权重的所有梯度

- 将梯度应用于每个权重

在PyTorch和Lightning中,伪代码看起来都像这样:

但这里是PyTorch和Lightning不同的地方。在PyTorch中,你自己编写了for循环,这意味着你必须记住要正确的顺序调用-这为BUG留下了很多空间。
即使你的模型很简单,一旦你开始做更高级的事情,例如使用多个GPU,梯度裁剪,提前停止,设置检查点,TPU训练,16位精度等,你的代码复杂性将迅速爆炸。
这是PyTorch和Lightning的验证和训练的循环代码:
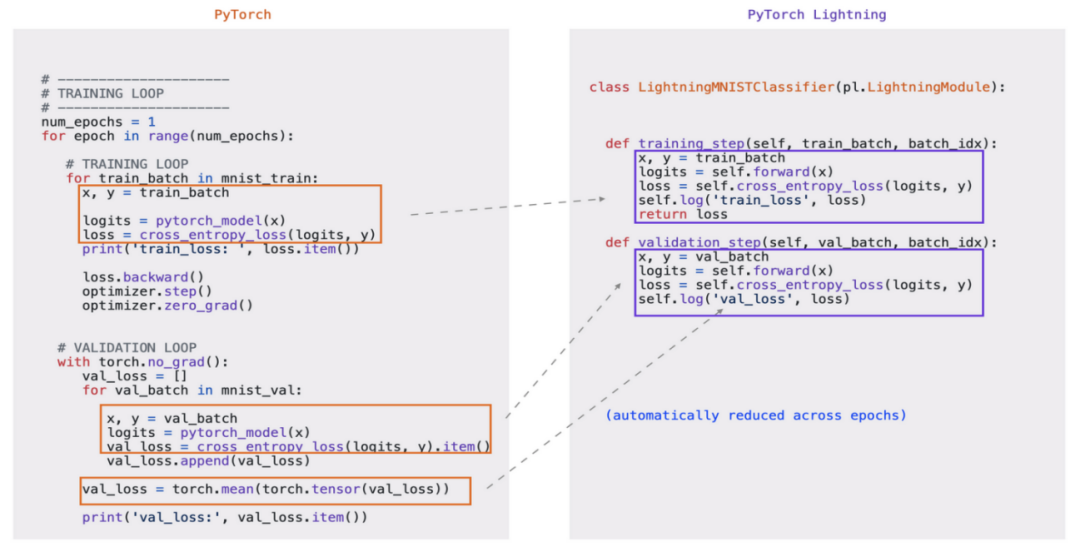
这就是Lightning代码的美。它抽象化样板代码(不在盒子中的代码),但其他所有内容保持不变。这意味着你仍在编写PyTorch,但你的代码结构很好。
训练器(trainer)是我们抽象样板代码的方式。
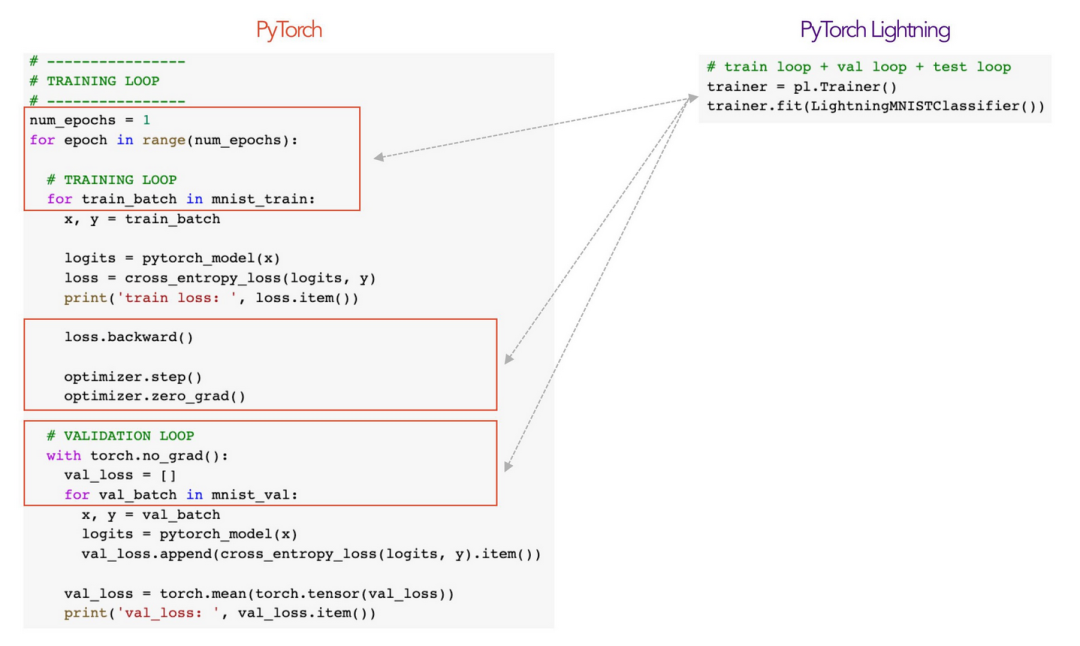
这非常简单,你要做的就是将PyTorch代码组织到LightningModule中。
这一篇中我们简单介绍了PyTorch Lightning ,大家对模型、数据、损失、优化器等关键要素的使用也有了一个基本了解。而在下篇中,我们会通过一个实际的示例 —— MNIST 项目来为大家介绍 PyTorch Lightning 的具体使用方法。
文章翻译自:https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09
原作者:William Falcon
(原文来源于网络,如有侵权请联络删除)
作者介绍:
马哲,海云捷迅研发工程师。毕业于山东农业大学信息科学与工程学院。10年软件开发经验,熟悉Linux、Docker、OpenStack、Kubernetes等开源技术并具有开源社区贡献经历。在云计算、人工智能等技术领域具有丰富的研究开发经验。